
Une stack IA locale, en 2026, n’est plus un projet de bricoleur du dimanche. Quatre briques open source matures (Ollama, Open WebUI, n8n, OpenClaw) suffisent à composer un environnement IA complet qui ne dépend d’aucun fournisseur cloud. Le pari de cet article n’est pas de vendre l’autonomie comme une religion : Claude Sonnet et GPT gardent des avantages bien réels. Il est de vous donner le mode d’emploi pragmatique pour monter votre propre stack ia locale, savoir quand elle remplace le cloud, quand elle le complète, et combien elle coûte sur douze mois face à un abonnement Pro.

Pourquoi une stack IA dev 100% locale en 2026
Confidentialité : santé, juridique, finance, R&D
Le moteur le plus solide derrière une stack ia locale s’appelle la confidentialité. En 2026, la majorité des acteurs santé, juridique, banque-assurance, défense ou R&D refusent d’envoyer leurs corpus dans un service cloud, même contractuel. Le RGPD, la directive NIS2, le Cyber Resilience Act et les politiques internes finissent par converger : si la donnée ne peut pas sortir, le LLM doit entrer. Ollama, Open WebUI et compagnie répondent exactement à ce besoin.
Coût récurrent vs investissement matériel
Un développeur qui consomme l’IA toute la journée brûle vite 30 à 80 euros par mois en API ou abonnements Pro. Sur trois ans, un Mac M3 Pro 18 Go bien amorti revient moins cher qu’un Claude Code Max et coupe la dépendance fournisseur. La courbe de rentabilité bascule plus tôt qu’on ne l’imagine, surtout pour une équipe de plusieurs développeurs ou un freelance qui mutualise son matériel.
Souveraineté et résilience
Une souveraineté tech, parallèle historique nous rappelle que la dépendance fournisseur a toujours été un point de fragilité. Une stack locale continue de fonctionner pendant les pannes OpenAI, dans un train sans 5G, sur un site industriel isolé, ou en zone à connectivité incertaine. C’est aussi un argument commercial fort en B2B sensible.
Les quatre briques de la stack
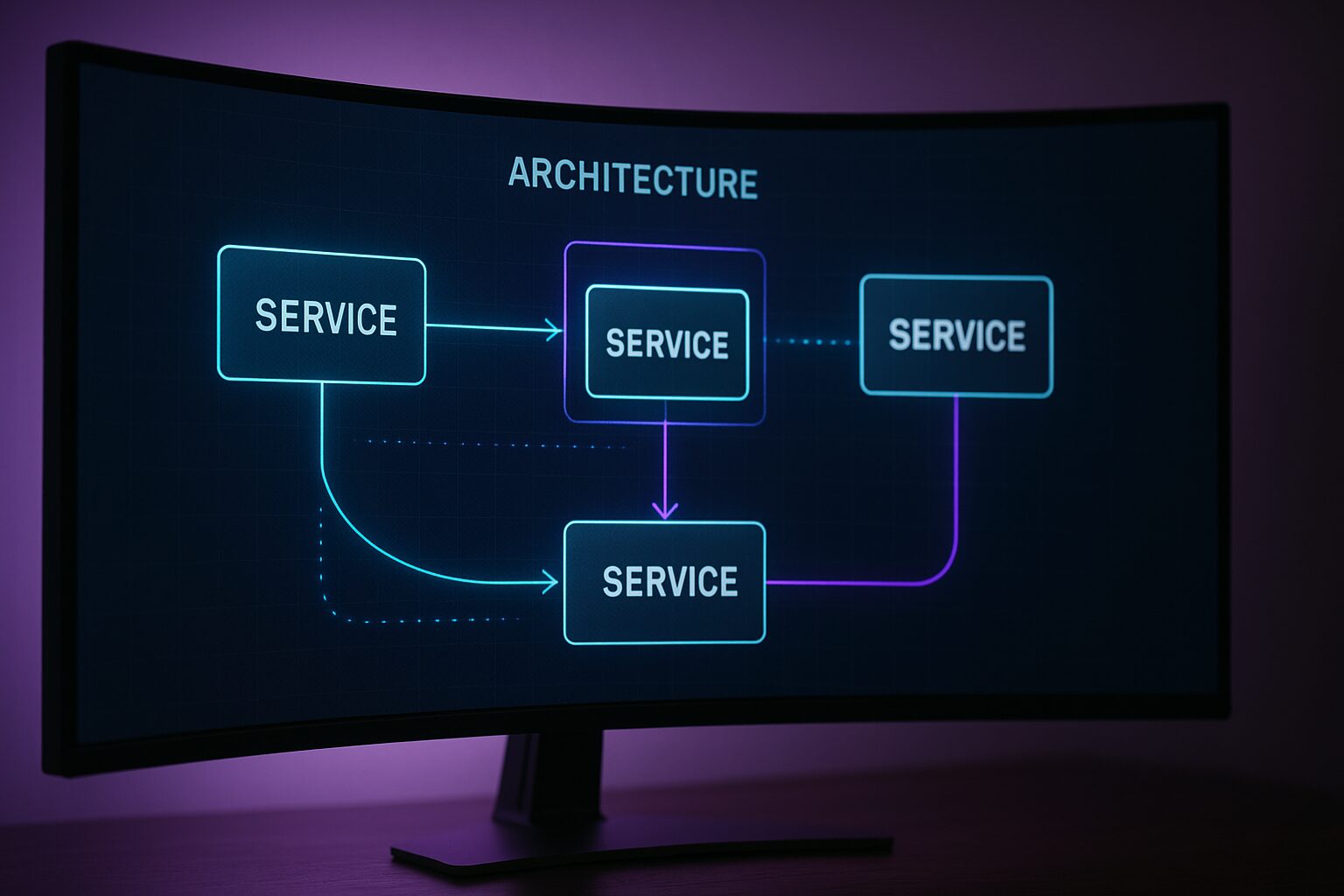
Une stack IA locale efficace tient en quatre composants spécialisés. Ils se parlent en HTTP local, chacun a une responsabilité claire, et tous tournent en un seul docker compose up.
| Brique | Rôle | Alternatives | Docker prêt | RAM/VRAM |
|---|---|---|---|---|
| Ollama | Moteur d’inference LLM | llama.cpp, vLLM, LM Studio | Oui (image officielle) | 8-24 Go VRAM |
| Open WebUI | Interface chat à la ChatGPT | LibreChat, AnythingLLM | Oui | 1 Go RAM |
| n8n | Orchestration agents et workflows | Make, Zapier (cloud), Activepieces | Oui | 1 Go RAM |
| OpenClaw | Assistant système multi-canal | Home Assistant, agent maison | Oui (beta) | 500 Mo RAM |
Ollama, le moteur d’inference
Ollama charge un modèle quantisé (un modèle compressé en 4 ou 8 bits par paramètre pour tenir en VRAM, Video RAM, la mémoire d’un GPU) et expose une API HTTP locale sur localhost:11434. Il joue le rôle de la centrale d’énergie : tout ce qui parle IA dans la stack passe par là. Le projet est open source sous licence MIT, dépôt principal sur github.com/ollama/ollama. Pour les détails CLI, modèles et Modelfile, voir l’installation et workflow Ollama.
Open WebUI, l’interface chat à la ChatGPT
Open WebUI offre une interface web complète (chat, historique, prompts sauvegardés, RAG sur documents, multi-modèles) qui se branche sur Ollama en deux variables d’environnement. C’est le lieu où vos collègues non-développeurs viennent dialoguer avec le LLM local sans toucher au terminal. Le projet est documenté sur docs.openwebui.com.
n8n, l’orchestrateur d’agents et de workflows
n8n est l’outil qui transforme une bibliothèque de modèles en agents qui font des choses : surveiller GitHub, traiter du mail, scraper, écrire dans Notion, déclencher un build. Il tourne en self-hosted Docker, accepte des nodes pour Ollama, Anthropic, OpenAI et LangChain, et permet de versionner ses workflows en JSON. La référence officielle vit sur docs.n8n.io ; voir aussi le détail dans le guide pour automatiser des workflows IA avec n8n.
OpenClaw, l’assistant système agnostique
OpenClaw est arrivé en janvier 2026 comme le « Jarvis open source » : un agent système TypeScript multi-canal (Telegram, Discord, Slack, WhatsApp, iMessage) agnostique du modèle. Il prend des commandes en langage naturel et exécute des skills (modules réutilisables qui parlent à GitHub, Obsidian, Spotify, votre calendrier). Là où n8n est un orchestrateur, OpenClaw est un compagnon conversationnel. Code source ouvert sur github.com/openclaw/openclaw. Détails projet dans OpenClaw, l’assistant système open source.
Comparaison pragmatique avec la stack cloud
Claude Code, Cursor, Copilot : ce qu’ils gardent
Le cloud garde trois avantages clairs en 2026 : la qualité brute (Claude Sonnet 4.5 et GPT-5 dépassent encore tout modèle local sur le raisonnement complexe et le contexte long), la fluidité d’usage (zéro maintenance, mises à jour gérées) et l’écosystème d’agents prébranchés (Claude Code, Cursor, Devin). Pour un développeur qui code des projets variés sans contrainte de confidentialité, c’est imbattable.
La stack locale : ce qu’elle gagne, ce qu’elle perd
La stack ia locale gagne sur la confidentialité (donnée scellée), le coût marginal (zéro après amortissement), la latence (pas de round-trip réseau) et la résilience (pas de dépendance fournisseur). Elle perd sur la qualité du raisonnement complexe, sur les modèles frontière, et sur la simplicité de mise à jour. Le compromis dépend de votre vrai mix de cas d’usage.
L’hybride raisonnable
La position pragmatique en 2026 est l’hybride : local pour le sensible et le volumineux (RAG sur codebase privée, génération de tests, traduction de docstrings, résumés de tickets), cloud pour le complexe et l’exceptionnel (refactor d’architecture, debug de problème ouvert, design de système). Un router simple dans n8n ou Claude Code décide où envoyer chaque requête. Voir aussi le panorama complet des agents IA autonomes en 2026.
Guide d’installation pas-à-pas

Prérequis matériels
Comptez 32 Go de RAM minimum, 100 Go de SSD libre, et soit un Mac M-series (M2 Pro et au-delà), soit un PC avec une RTX 4070 Ti 16 Go ou supérieure. Docker Desktop ou un Docker natif Linux. Pour faire tourner du 14B en parallèle d’Open WebUI et n8n, visez 16 Go de VRAM dédiée ou 24 Go d’unified memory.
Installer Ollama et tirer 2-3 modèles
curl -fsSL https://ollama.com/install.sh | sh
ollama pull qwen2.5-coder:14b
ollama pull llama3.3:8b
ollama pull nomic-embed-textTrois modèles : un coder, un généraliste, un d’embeddings pour le RAG (Retrieval Augmented Generation, technique qui injecte des extraits documentaires dans le prompt avant la réponse).
Lancer toute la stack avec docker-compose
services:
open-webui:
image: ghcr.io/open-webui/open-webui:main
ports: ["3000:8080"]
environment:
- OLLAMA_BASE_URL=http://host.docker.internal:11434
volumes: [open-webui:/app/backend/data]
n8n:
image: n8nio/n8n:latest
ports: ["5678:5678"]
environment:
- N8N_BASIC_AUTH_ACTIVE=true
- N8N_BASIC_AUTH_USER=admin
- N8N_BASIC_AUTH_PASSWORD=changeme
volumes: [n8n_data:/home/node/.n8n]
openclaw:
image: openclaw/openclaw:beta
ports: ["7654:7654"]
environment:
- MODEL_PROVIDER=ollama
- OLLAMA_HOST=http://host.docker.internal:11434
volumes: [openclaw_data:/data]
volumes:
open-webui:
n8n_data:
openclaw_data:Un docker compose up -d, et vous avez Open WebUI sur :3000, n8n sur :5678, OpenClaw sur :7654, tous branchés sur le Ollama hôte. Les versions testées en mai 2026 : Ollama 0.5.x, Open WebUI 0.6.x, n8n 1.85.x, OpenClaw beta 0.4.x.
Brancher OpenClaw sur Ollama
Dans l’interface OpenClaw (localhost:7654), section Models, sélectionnez ollama, choisissez qwen2.5-coder:14b comme modèle par défaut, ajoutez vos canaux (Telegram bot token, webhook Slack), activez les skills GitHub et Obsidian. Le tout en moins de quinze minutes.
Trois cas d’usage concrets
RAG local sur codebase et documentation
Open WebUI propose nativement un onglet « Documents » : vous y déposez votre codebase et votre documentation, il indexe via nomic-embed-text, et chaque conversation peut s’appuyer sur ces sources. Pour une équipe interne, c’est le ChatGPT-qui-connaît-votre-projet sans rien laisser fuiter. Combinez avec la stratégie de générer des tests sur du code sensible pour fermer la boucle qualité.
Agent n8n qui revoit les PR GitHub avec Ollama
Workflow type : webhook GitHub pull_request.opened, récupération du diff via API, prompt Ollama « voici un diff, donne-moi une revue critique en français orientée bugs, perf et sécurité », commentaire posté automatiquement sur la PR. Vous obtenez une revue first-pass cohérente sur 100% de vos PR sans dépenser un centime cloud. Voici un export n8n minimal du workflow, prêt à importer dans votre instance et à versionner en Git.
{
"name": "PR review local Ollama",
"nodes": [
{
"parameters": {
"httpMethod": "POST",
"path": "github-pr-opened",
"responseMode": "onReceived"
},
"id": "webhook-1",
"name": "GitHub Webhook",
"type": "n8n-nodes-base.webhook",
"typeVersion": 1,
"position": [240, 300]
},
{
"parameters": {
"url": "=https://api.github.com/repos/{{$json[\"repository\"][\"full_name\"]}}/pulls/{{$json[\"pull_request\"][\"number\"]}}",
"authentication": "headerAuth",
"options": { "headers": { "Accept": "application/vnd.github.v3.diff" } }
},
"id": "http-1",
"name": "Fetch PR diff",
"type": "n8n-nodes-base.httpRequest",
"typeVersion": 4,
"position": [480, 300]
},
{
"parameters": {
"url": "http://host.docker.internal:11434/api/generate",
"method": "POST",
"jsonParameters": true,
"bodyParametersJson": "={\n \"model\": \"qwen2.5-coder:14b\",\n \"stream\": false,\n \"prompt\": \"Tu es un relecteur senior. Voici un diff de PR. Donne une revue critique en francais, structuree en bugs, perfs, securite, lisibilite. Sois concis.\\n\\n{{$json[\"data\"]}}\"\n}"
},
"id": "ollama-1",
"name": "Ollama generate",
"type": "n8n-nodes-base.httpRequest",
"typeVersion": 4,
"position": [720, 300]
},
{
"parameters": {
"url": "=https://api.github.com/repos/{{$node[\"GitHub Webhook\"].json[\"repository\"][\"full_name\"]}}/issues/{{$node[\"GitHub Webhook\"].json[\"pull_request\"][\"number\"]}}/comments",
"method": "POST",
"authentication": "headerAuth",
"jsonParameters": true,
"bodyParametersJson": "={\n \"body\": \"Revue automatique (Ollama qwen2.5-coder local) :\\n\\n{{$json[\"response\"]}}\"\n}"
},
"id": "comment-1",
"name": "Post PR comment",
"type": "n8n-nodes-base.httpRequest",
"typeVersion": 4,
"position": [960, 300]
}
],
"connections": {
"GitHub Webhook": { "main": [[{ "node": "Fetch PR diff", "type": "main", "index": 0 }]] },
"Fetch PR diff": { "main": [[{ "node": "Ollama generate", "type": "main", "index": 0 }]] },
"Ollama generate": { "main": [[{ "node": "Post PR comment", "type": "main", "index": 0 }]] }
},
"active": false,
"settings": { "executionOrder": "v1" },
"versionId": "1.0.0"
}Quatre nodes : un webhook GitHub, un fetch du diff via l’API, un appel HTTP vers localhost:11434 qui interroge Qwen2.5-Coder, un POST de commentaire sur l’issue/PR. Auth GitHub par token PAT en header, modèle Ollama tournant sur l’hôte, zéro appel cloud sortant.
OpenClaw + Ollama sur Telegram, assistant système offline
Vous écrivez à votre bot Telegram : « résume les issues critiques ouvertes hier sur mon repo », « capture cette idée dans Obsidian », « lance le mode focus, coupe Slack une heure ». OpenClaw exécute via ses skills, sans qu’aucun message ne quitte votre infrastructure (l’API Telegram étant la seule sortie réseau, et chiffrée). Pour aller plus loin, il est possible de brancher MCP sur Ollama et n8n et exposer vos services internes comme outils à l’agent.
Limites et pièges
Latence et qualité vs Claude Sonnet
Sur un Mac M3 Pro avec Qwen2.5-Coder 14B, comptez 25 à 35 tokens par seconde. C’est rapide, mais pas instantané. La qualité tient sur du code direct, descend sur le raisonnement multi-étapes long. Soyez lucide : pour un debug ouvert dans un legacy, Claude Sonnet 4.5 reste plus efficace en temps total, même avec sa latence cloud.
Maintenance : versions, modèles, drivers
Une stack locale demande 2 à 4 heures de maintenance par mois : montée de version Ollama, drivers GPU, nouveaux modèles à tester, mises à jour Open WebUI et n8n. Sur un poste de dev, c’est tenable. Sur un serveur partagé d’équipe, cadrez un responsable et un cycle de mise à jour clair.
Quand l’hybride reste plus malin
Si 80% de votre IA quotidienne consiste en raisonnements complexes, design de système, ou exploration de bases de code énormes, le 100% local va frustrer. Restez en hybride : local pour le confidentiel et le volume, cloud pour l’exceptionnel. Le pilier brancher MCP sur Ollama et n8n détaille comment maintenir un seul protocole de communication des deux côtés.
Coût total sur 12 mois : local vs cloud
Voici trois scénarios concrets, en euros TTC, sur douze mois pour un usage IA dev intensif (équivalent 50 millions de tokens / mois en cloud).
| Scénario | Investissement initial | Coût récurrent / mois | Total 12 mois |
|---|---|---|---|
| Mac M3 Pro 18 Go (achat) | 2 599 € | 0 € (électricité ~5 €) | 2 659 € |
| PC Ryzen + RTX 4070 Ti Super 16 Go | 1 800 € | 0 € (électricité ~8 €) | 1 896 € |
| Mini-serveur Hetzner GPU GEX44 | 0 € | ~250 € | 3 000 € |
| Claude Code Pro × 12 mois | 0 € | ~100 € | 1 200 € |
| Claude Code Max × 12 mois | 0 € | ~200 € | 2 400 € |
Lecture rapide : sur un an, Claude Code Pro reste moins cher en cash que l’achat matériel. Sur deux ans, l’achat passe devant. À partir de la troisième année, l’écart se creuse en faveur du local. Mais le calcul change radicalement dès qu’il y a une équipe (un serveur GPU partagé entre 5 développeurs amortit en 6 mois) ou des données qui ne peuvent pas sortir.
Questions fréquentes
Quelles sont les briques d’une stack IA dev 100% locale en 2026 ?
Quatre briques suffisent : Ollama pour faire tourner les modèles (moteur d’inference), Open WebUI pour l’interface chat à la ChatGPT, n8n pour orchestrer des agents et des workflows, OpenClaw pour l’assistant système multi-canal (Telegram, Slack, Discord). Chacune est open source, dispose d’une image Docker officielle, et se branche sur les autres en HTTP local. Un seul docker-compose monte l’ensemble.
Combien coûte une stack IA locale comparée à Claude Code Pro ?
Une stack ia locale demande 1 800 à 2 600 euros d’investissement matériel one-shot (Mac M3 Pro ou PC RTX 4070 Ti) pour zéro coût récurrent ensuite. Claude Code Pro coûte environ 1 200 euros sur douze mois et Max environ 2 400 euros. Le break-even se situe autour de 18 à 24 mois pour un usage solo. Pour une équipe ou des données sensibles, le local devient rapidement plus rentable.
Quel matériel minimum pour faire tourner une stack IA dev en local ?
Le seuil utile en 2026 est 32 Go de RAM, 16 Go de VRAM dédiée (ou 24 Go d’unified memory sur Mac M-series), 100 Go de SSD libre. Un MacBook Pro M3 Pro 18 Go, un PC Ryzen 7 + RTX 4070 Ti Super 16 Go, ou un mini-PC Framework avec GPU externe font le job. En dessous, vous serez limité aux modèles 7B et perdrez en qualité.
Une stack IA locale remplace-t-elle Claude ou GPT ?
Pas pour tout. Les modèles frontière (Claude Sonnet 4.5, GPT-5) gardent en 2026 un avantage net sur le raisonnement complexe, le contexte ultra-long et les tâches exploratoires ouvertes. La stack locale excelle sur les volumes répétitifs (génération de tests, résumés, traduction, RAG), les contraintes de confidentialité et les contextes offline. La position raisonnable est l’hybride.
Peut-on faire du RAG sur sa codebase en local ?
Oui, et c’est même l’un des cas d’usage les plus convaincants. Open WebUI gère un RAG natif via le modèle d’embeddings nomic-embed-text servi par Ollama. Vous déposez votre repo, vous posez des questions en langage naturel, et le système retrouve les bons fichiers avant de répondre. Aucune ligne de code ne quitte votre machine. Pour des cas plus avancés, n8n permet de construire un pipeline RAG custom avec un vector store dédié type Qdrant.
Vous avez des données sensibles que vous ne pouvez pas envoyer dans le cloud, ou un volume IA qui pèse sur votre stack ia locale à venir ? On peut concevoir l’architecture ensemble.